|
Sabre |
| Data preparation: Introduction | |
Sabre manual |
A Statistical
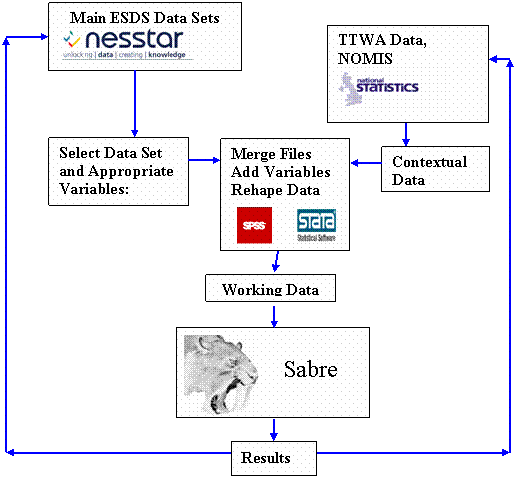
Analysis/Modelling Cycle This is a schematic to represent the various stages a quantitative researcher may go through during their research in a substantive area using individual level panel or clustered data from secondary sources. There are other types of quantitative research, e.g. using aggregate level data, these are not covered here. The top part of this diagram is concerned with data set selection, data management and preparation, the lower part represents the analysis part. In this example, the data selection stage is done using Nesstar on data sets in a data archive. In the past, this stage would be performed by reading hard copy data descriptions and by ploughing through coding schedules and questionnaires by hand. Much of this work has been made easier by through the use of online metatdata and resource discovery tools by the data archives. However the on line surveys of individual behaviour typically do not contain relevant contextual information, such as would occur in a study of labour market or occupational mobility where the researcher needs some measure of the opportunities and activities in the Travel to Work Area of the respondent. These differences can have a major effect on an individual’s behaviour. In this figure the TTWA data is obtained from NOMIS. Having
selected the relevant contextual data (it may need to be disaggregated to the
appropriate spatio-temporal scale, e.g. month and Travel
To Work Area (TTWA)) it is added to the individuals records. This is often done
in standard desktop software such as SPSS or Stata. The
resulting file is then manipulated to put it in a form (working data) appropriate
for the analysis. This working data set is then transferred/saved in the text format
needed for Sabre. The analysis is performed and if the researcher finds
problems with the analysis, e.g. missing values in a variable make it
impossible to use (or the referees suggest a modified analysis), the researcher
goes back to the data management step and selects alternative or additional
variables, depending on results. This cycle can be repeated 2 or 3 times. The
data management step could be much more complex than this, e.g. with the British
Household Panel Survey there are 30
files with related data that may need to be combined to produce a coherent data
set (e.g. work history data) and this type of data base management can not
currently be performed in Nesstar. However, many of the data sets we use to illustrate Sabre in this site are much simpler as they have individual specific but time constant explanatory variables for the responses of interest. In this case the data can be arranged in a compact wide form. Sabre concentrates on procedures for estimating random effect models, it only has a few commands for performing simple transformations. For instance it does not have the facilities for handling data with missing values, reshaping data, or manipulations like sort on a particular variable, so these activities are best performed in more general statistical software packages. The commands we use in this section on data preparation are for Stata 9. The Stata versions of the data sets we refer to in this section are not available from this site. We do provide references that will help you find them. Other software such as R and SPSS could also be used to perform the types of data set preparation we describe here. Our
notes are not meant to be comprehensive as there are many sites that provide an
introduction to Stata and some of the commands we
present here, see for e.g. http://www.ats.ucla.edu/stat/stata/.
|
Other links: Centre for e-Science | Centre for Applied Statistics